
今天最主要談論的問題是要如何透過添加適當的特徵來改善模型的準確率;一樣先創建notebooks接著切換至training-data-analyst> courses> machine_learning> deepdive> 04_features打開a_features.ipynb,開始進行實驗。
首先當然是引入相關套件與所要使用的資料,這次使用的是房屋的資料集
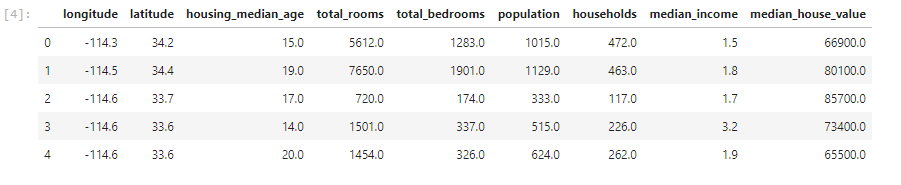
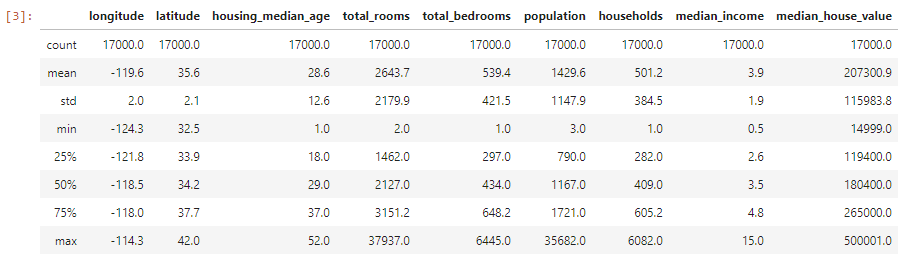
pandas讀取csv檔,pd.read_csv("路徑")接著可以利用head()、describe()來看文件內的內容
之後我們必須分測試與驗證集
np.random.seed(seed=1)
rand()函數做切割
這邊定義一個函數
def add_more_features(df):
df['avg_rooms_per_house'] = df['total_rooms'] / df['households']
df['avg_persons_per_room'] = df['population'] / df['total_rooms']
return df
def make_input_fn(df, num_epochs):
return tf.estimator.inputs.pandas_input_fn(
x = add_more_features(df),
y = df['median_house_value'] / 100000,
batch_size = 128,
num_epochs = num_epochs,
shuffle = True,
queue_capacity = 1000,
num_threads = 1
)
完成上述設定可以自己定義feature columns看你要接受的參數有哪些
tf.feature_column.numeric_column來做設定最後一個函數設定則是要定義如何同時訓練與驗證
def train_and_evaluate(output_dir, num_train_steps):
estimator因為是輸出結果是連續,所以利用LinearRegressor
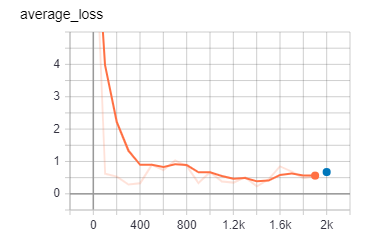
TrainSpec、EvalSpec輸入位子與所需幾個步驟,並且EvalSpec加入start_delay_sec(晚幾秒開始)、throttle_secs(每幾秒驗證一次)這兩個參數tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)完成宣告最後一步當然是開始做訓練
OUTDIR = '輸出位置'
shutil.rmtree(OUTDIR, ignore_errors = True)、tf.summary.FileWriterCache.clear()來重新整理以及清除快取

 iThome鐵人賽
iThome鐵人賽